

















ContextiLearn
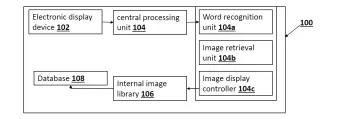
This invention provides a smart learning system that helps users understand written content more easily by instantly showing relevant images for selected words in a text. When a reader taps or clicks on a word, the system automatically displays a context-appropriate visual representation without leaving the document.
The invention works on common devices such as computers, tablets, and smartphones and does not require any special hardware or internet connection. By combining text and visuals in a seamless way, the system improves comprehension, engagement, and memory retention, especially for students, children, and learners who benefit from visual support.
This patented technology is well suited for use in education, e-learning platforms, digital books, language learning tools, and accessibility solutions, offering a simple yet powerful way to make learning more interactive and effective.
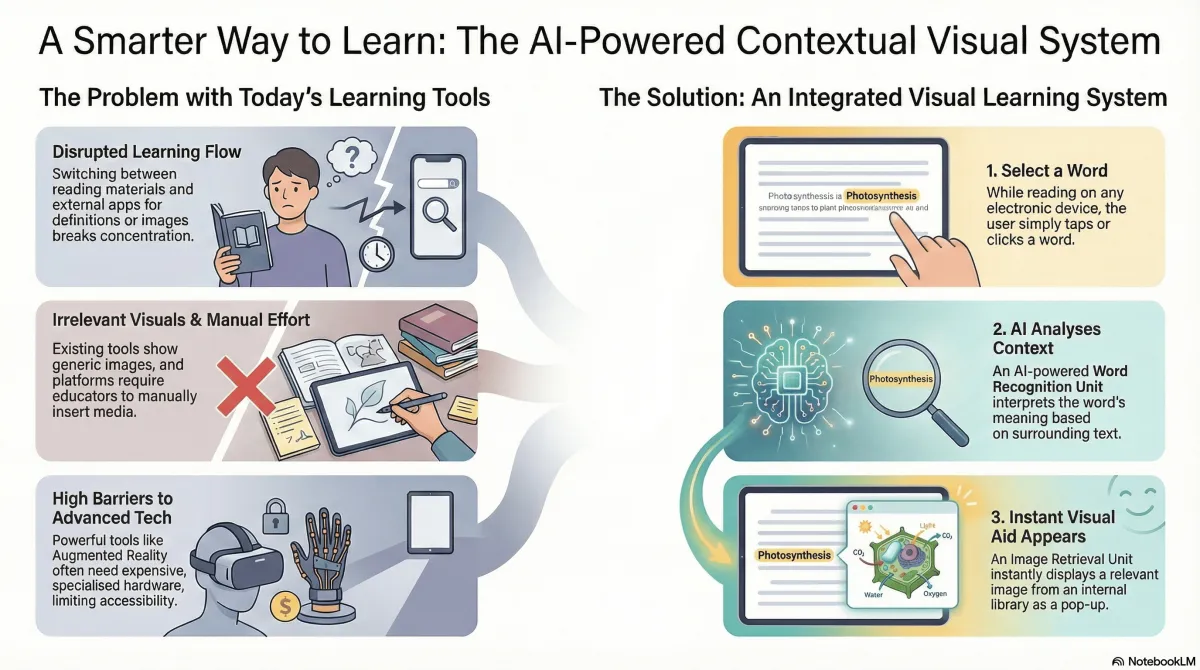
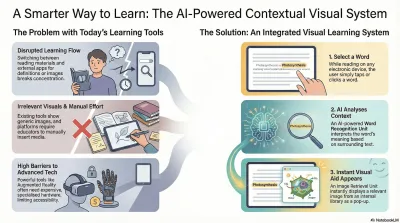
Digital learning and content platforms rely heavily on text, which limits user engagement, comprehension, and retention. When users encounter unfamiliar terms, they must leave the content to search for explanations or visuals, increasing drop-off rates and reducing learning efficiency.
Current solutions either require manual content creation by educators and publishers or depend on complex and costly technologies. These approaches do not scale well and fail to deliver real-time, context-aware visual support within the reading experience.
As a result, there is a clear market gap for a scalable, cost-effective technology that seamlessly connects text with relevant visual understanding, improves user engagement, and enhances the overall value of digital content across education, publishing, and training platforms.
The invention provides a patented, software-based system that seamlessly integrates contextual visual learning into digital text content. It enables readers to instantly view relevant visual representations of words or concepts while reading, without leaving the document or interrupting the learning flow.
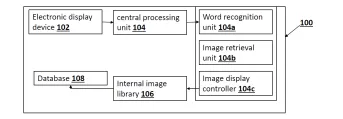
When a user selects a word in a digital text, the system automatically identifies the word and retrieves a context-appropriate image from an internal or curated image library. The visual is displayed immediately on the same screen, allowing users to understand unfamiliar or complex terms in real time. This removes the need to search externally for explanations or visuals, significantly improving engagement, comprehension, and retention.
The solution is designed to work on standard electronic devices such as computers, tablets, and smartphones, requiring no special hardware or complex setup. It can function with or without internet connectivity, making it suitable for a wide range of environments, including classrooms, homes, and low-infrastructure regions. The system is scalable and adaptable across different subjects, languages, and learning levels.
From a business perspective, the invention addresses a critical gap in digital education and content platforms by automating visual support within text-based materials. Unlike traditional learning tools that rely on manual content creation or static multimedia, this system dynamically delivers visual context at the point of need. This reduces content development costs for educators and publishers while enhancing the value and effectiveness of digital materials.
The technology is applicable across multiple industries, including education technology, e-learning platforms, digital publishing, corporate training, accessibility solutions, and language learning applications. It can be integrated into existing software platforms as a licensed feature, embedded module, or standalone application.
By improving user engagement and learning outcomes while remaining cost-effective and easy to deploy, the invention offers a strong commercial advantage to organizations seeking differentiation, higher user retention, and enhanced educational impact. This patented solution enables businesses to deliver smarter, more interactive digital experiences without increasing complexity or operational overhead.
Yes, the invention addresses a significant and well-recognized gap in prior art related to digital learning and content interaction.
Most existing educational and digital reading solutions rely primarily on text-based content, with visual support either being static, manually embedded, or provided through external tools. In many cases, learners must leave the reading environment to search for images, definitions, or explanations using separate applications or web searches. This fragmented approach disrupts the learning flow, reduces user engagement, and negatively impacts comprehension and retention.
Some platforms, such as e-book readers and learning management systems, offer limited multimedia support; however, these systems typically depend on predefined content or manual insertion of images by educators or content creators. This makes the process time-consuming, costly, and difficult to scale across large volumes of content. Moreover, the visual materials provided are often generic and not dynamically adapted to the specific context in which a word or concept appears.
Advanced solutions such as augmented reality (AR)–based learning tools attempt to improve engagement through immersive experiences, but they introduce new limitations. These systems often require additional hardware, higher implementation costs, and technical expertise, making them unsuitable for widespread adoption in everyday educational and training environments.
The key gap in prior art is the lack of a simple, automated, and scalable solution that provides real-time, context-aware visual support directly within digital text content. Existing technologies do not offer a seamless method for dynamically linking words in a document to meaningful visual representations at the moment of reading, without interrupting the user experience or increasing operational complexity.
The present invention fills this gap by introducing a system that automatically recognizes selected words in a text and instantly displays relevant visual aids within the same interface. This approach eliminates the need for external searches, manual content creation, or specialized hardware. By embedding contextual visual learning directly into standard digital documents, the invention delivers a continuous, intuitive, and more effective learning experience.
In addition, the invention improves accessibility for diverse learners, including children, language learners, and individuals who benefit from visual reinforcement. From a commercial perspective, it enables education providers, publishers, and digital platforms to enhance user engagement and learning outcomes while reducing content development effort and cost.
By addressing these limitations of prior art, the invention establishes a clear technological and commercial advancement in contextual digital learning systems.
-
Instant, Contextual Visual Learning: Shows relevant images for selected words in real time, keeping users engaged without leaving the document.
-
Fully Automated & Scalable: Automatically retrieves and displays visuals, reducing manual effort and supporting large-scale digital content.
-
Works on Standard Devices: Compatible with computers, tablets, and smartphones—no special hardware required.
-
Versatile & Adaptable: Suitable for classrooms, e-learning, publishing, corporate training, and accessibility solutions.
-
Patent-Protected Product & Method: Broad protection covering both the system and the workflow, making it attractive for licensing and commercialization.
Industries where the invention can be useful?
Education / EdTech E-Learning Platforms Digital Publishing / E-Books Corporate Training / HR Tech Healthcare / Medical Education Accessibility / Assistive Technology Consumer Electronics / Educational Devices Artificial Intelligence (AI) / Multimodal AI Libraries / Digital Archives Marketing / Interactive Advertising Language Learning / Translation Apps Tourism & Travel EducationAn estimate of the total addressable market?
The invention addresses multiple high-growth markets, including education technology, e-learning, digital publishing, corporate training, and accessibility solutions. The global total addressable market is estimated at $500–600 billion, driven by the rapid adoption of digital learning tools, AI-enhanced educational platforms, and inclusive learning technologies. This represents a significant commercial opportunity for licensing, integration, and scalable deployment across diverse sectors.Potential Customers/End Users. Who might benefit?
Schools, colleges, and universities (including special education programs) EdTech companies and online learning platforms Digital publishers and interactive content providers Corporate training providers and LMS platforms Healthcare and medical education organizations Accessibility and assistive technology providers Individual learners and language learning usersDocuments
-
1766041808946_377.pdf
Actions
Added all portfolio
| Country | Current Status | Patent Application Number | Patent Number | Applicant / Current Assignee Name | Title | Google Patent Link |
| India | Granted | 202441079301 | 574719 | Dr. Anu Thomas | A SYSTEM FOR CONTEXTUAL VISUAL LEARNING AND A METHOD FOR THE SAME | Google patent link |
You may also like the following patent